When it comes to structuring a React app, the ideal structure is the one that allows you to move around your code with the least amount of effort.
In this post, I'd like to tell you how I structure my React apps, and what drove my decisions. Along the way I'll mention some options I don't use because they don't suit me, but that might serve you well.
I'd also like to hear how you do things and what you've found works well down in the comments.
What works for you
Maybe this was always obvious to you, but it's only just clicked for me: the structure of an app has nothing to do with computers.
Imagine for a moment an app with only one file for all your components, reducers, the store, utilities, everything.
A terrible idea, of course. Now, have a think about why the above would be a bad thing.
We both know you didn't really stop and ponder, so I'll just tell you what I think. The problem with this giant file is that it's going to be difficult to navigate. But what if you could have bookmarks for each area of the code, maybe one bookmark per function. Maybe the ability to have nested bookmarks. How about a table of contents for all of these bookmarks?
This might seem like a daft thought experiment, but I think it's worth establishing that the only thing you're trying to do when deciding on a file structure is to maximise how easily you can navigate through your code. Your ‘files' are nothing more than markers to parts of the code that will wind up being a single chunk of JS at the end of the day.
And this is why you can never get a straight answer to the question “what's the best way to structure my app” — it depends so much on your own navigation habits and preferences that it's not a question anyone else can answer for you.
To work out what the 100% correct application structure was for me, I set out to quantify my most common code-related activities:
- Create a new component. Usually this is a copy/paste of some existing component.
- Import one module into another. Here I mean the actual typing out of
import { SomeComponent } from '../blah/de/blah.js';. - Jump to source. This is when I'm looking at a file, and it has a reference to something external, say a
<HeaderNav>component, and I jump to where that component is defined. - Open a known file. Probably doesn't need a description, but I want my bullet points to look nice and uniform, so this is where I think in my head “I want to open the header nav”, so I use a keyboard shortcut and type the file name to open it. Dammit, now this is the bullet point with the longest description and it didn't even need one in the first place.
- Browse for a file I don't know the name of. Maybe I didn't work on the little widget that shows the drop down below the user profile photo and don't know what it's called. So I want to go browsing the directory structure for this component.
- Change tab to another open file. This is exactly what it sounds like. I currently have 7 files open, and I want to switch from one tab to another, by clicking on a tab name (or using the keyboard).
Next, I had a think about how often I do each of these things. I went back and counted the components I've created in the last year, the average number of imports per file, and took some wild guesses at the others, to come up with the following:
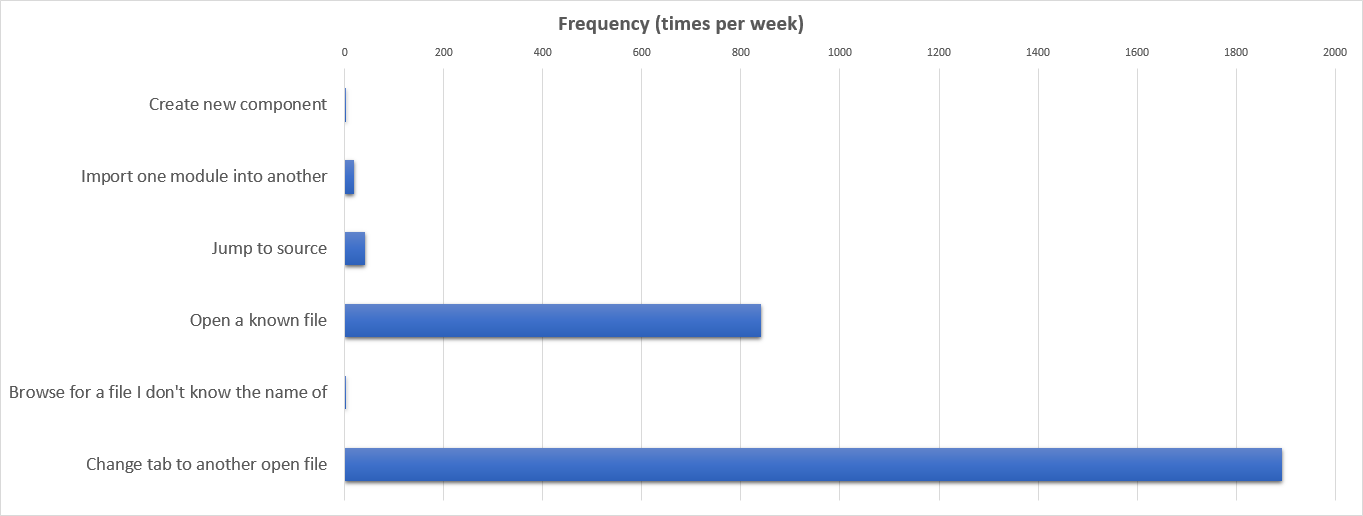 Sorted by the order that I thought of the things
Sorted by the order that I thought of the things
With this data in my hot little hands, I was ready to objectively look at all the aspects of structuring a React app. Let us go through them one by one.
Directory structure
As a general rule, if a module (a utility, component, etc.) is only used within another module, then I want it nested in the directory structure like so:
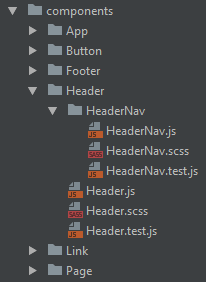
<HeaderNav> will only be referenced from within the <Header> component, so it lives as a child. A <Button> could be referenced from anywhere, so it lives at the top level.
That rule is great, but I also know that following a super strict set of rules here can be annoying. Technically everything resides under App and under Page too. But I'm not going to represent that in my directory structure, because I don't want to.
This might sound flippant but it's quite fundamental. If following your own rules creates a structure that is harder to navigate, you've taken your eyes off the prize.
Outside of components, I don't think directory structure is very important. You can agonise over whether your reducers and your action creators should be in the same directory as your services until you're a shade of blue. But if you ask me, any basic structure with sane folder names (actionCreators, reducers, data, etc.) is all you need.
This may be the first point where we differ in our needs and wants. I have established that I rarely open files by browsing through a directory structure, so naturally I apply a lower importance to directory structures. I've also never worked on a project with more than a few hundred components.
If you rely more heavily on navigating a directory structure, or you're Facebook with 30,000 components, then your needs will likely vary.
Another thing: I would suggest naming your components in a ‘fully qualified' (and globally unique) way. For example, HeaderNav is inside Header, so you could argue that it could just be named Nav. If that suits you, cool. But I open files by typing their names, and look at the text on tabs to switch files. In both these cases, having a fully qualified name is useful.
And of course if you're following BEM where the block matches the component name, you're going to need globally unique component names anyway.
What about container components?
Container components are a tricky one, because they're sort of components, but sort of not.
I see two broad approaches to fitting container components into your structure:
- Treat them exactly like presentational components
- Leave them out of the directory structure. They will live ‘in the background', just providing data to a component
In the first case, you would actually reference the container component in your markup. So, with the example of a header component that has its own container, it might be included like so:
So here I'm passing through some specific data to the <Page> and <Footer> components, while it's quite clear that the <HeaderContainer> is going to look after its own data needs.
If this is how you roll, the logical structure will be something like this:
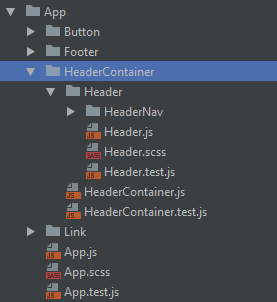
The second option is to leave container components out of the structure; to think of them like implementation details of the component that they wrap.
So maybe your <Header> would wrap itself in a container component at the point of export. Something like this:
And then you reference it like this:
The downside is that it isn't immediately clear that <Header /> will be provided data from somewhere else. The upside is one less step in the component hierarchy.
If this is how you want to do things, you can then just have the container as a function that lives in the same directory as the component it provides data to:
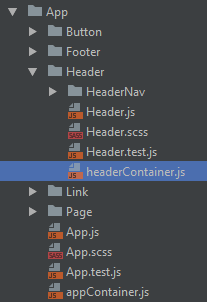
(Also note that I exported the ‘raw' Header as well as the default export of the container-wrapped Header. The former is for unit tests, and your linter might tell you that you're being confusing by exporting a non-default constant with the same name as the file. I tend to agree with the linter.)
I have used the first approach in a medium sized project and it worked quite well. I recently tried out the second example in a new project (that only has 6 container components) and it didn't quite feel right, so I'll stick with the first option.
I see no problem with either approach.
Side note: I think there's a fine art to recognising the point at which it makes sense to say “you know what, it doesn't really matter” and moving on with your day. This article nails it and is a nice short read. (Warning: there's a swear word in the title of that article, so don't click the link if you're offended by the word fuck.)
Self-contained components
My rule: if I have a project with more components than a Klein bottle has sides, I put each component in a directory along with a CSS file and a test. This rule is common for good reason, but even if you do have everything neatly tucked away in the same directory, you're still quite free to make one huge mistake…
Take a look at your nearest file that contains a component. At the top of that file you will probably see a list of all other files that the component relies on as a neat set of imports.
Unless, that is, you share CSS classes between components. Then you also have a bunch of dependencies that aren't listed.
Sure, you will save 7 seconds by using that .modal-wrapper class in your <DropDown> component because it already had the shadow you wanted, but oh boy do you even know the world of pain that you have just inflicted upon your future self...
[deleted scene: 14 paragraph rant about why this is a bad idea]
Trying to convince some people to not share CSS classes between components is like trying to convince people to “avoid using global variables in JavaScript” or “vaccinate your chickens” — some folks just aren't gonna listen.
CSS-module users are no doubt wiggling their butts feeling pretty darn pleased with themselves right now. And they have good reason to be — they have a setup that can enforce the explicit import of CSS classes. If you care about keeping your CSS tightly coupled with your components, you should be using CSS modules too.
File naming
One rule that I find immensely useful is this:
name your file the same as the thing you're exporting from that file
To some this is not even worth typing out it's so obvious. But I've seen plenty of code where this isn't the case and boy does it make it slow to move around.
(Don't forget, all of this is personal. When I say “slow to move around”, it's totally OK for you to think “it wouldn't make it slow for me”, and therefore decide that there is no point in naming a file the same as its default export.)
Something I do very often is open a file by typing its name. If I have a utility function called toString then I fully expect that I will have a file called toString that I can open by typing exactly that. Something else that I do very often is switch tabs to a file that I already have open. For this I'll expect that tab to have “toString.js” as it's name.
Structures like the below make me want to curl up in a ball in a fireplace that is in use:
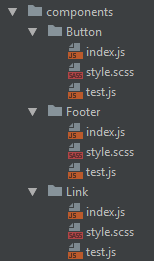
It staggers me that some people are happy to work like this.

Even if your IDE is clever and puts the directory in the tab name for non-unique filenames, you still have a bunch of redundancy there, and will run out of tab room sooner, and you still can't type the filename to open it. I don't even need to try this approach to know I won't like it. Like my cousin's new band, Mass Spectrometer that “don't really fit into any known genre”. Get someone else to drive you to the gig.
Having said that, I understand that there is reasoning behind this — it means your import statement is this:
**import** Link **from** '../Link';Instead of this:
**import** Link **from** '../Link/Link';It's a clear trade-off. Shorter import statements vs file names that match exports.
Let's me just look this up… I import a module into another module, on average, 18 times a week. I open a file by typing its name roughly 840 times a week, and I look for a name on a tab roughly 1,892 times a week.
So I'll take one extra (auto-completed) word in my import path, thanks.
Savvy readers will be shouting at their screens: there are two solutions to this that allow you have the file name match the thing being exported, and avoid having to type it twice in the import statement.
The first is to put an index.js file in every directory that exports a component, like so:
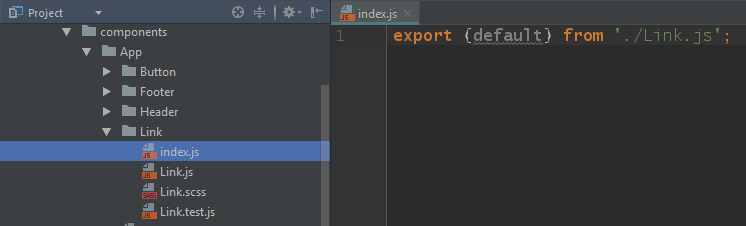
Since Node will look for an index.js file when resolving an import path, a path to ../Link is really a path to ../Link/index.js which is a file that points to the actual component file.
If typing fewer characters in your imports is important, then maybe an extra file for every directory sounds like good value. I think it's a bad deal and I will repeat one more time that it's seriously OK to have a different opinion on the matter.
The second ‘solution' is this monstrosity:
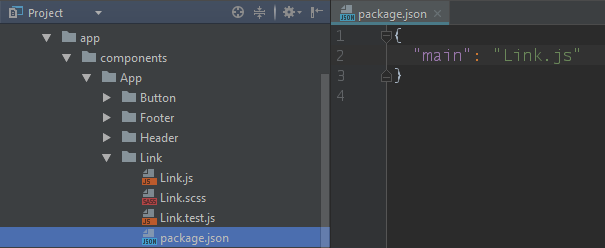
By this point you will know that if Node doesn't find ../Link/index.js it's going to check to see if ../Link/package.json exists. If it does, it's going to resolve to the value of the main property.
I think you have to really really hate typing one extra word in your import statements to go as far as creating a package.json file for every component. It's just weird. And the more weird shit you put in your code, the weirder you become.
These two types of ‘redirecting' files both mean that your import statement no longer points to the file where the thing is defined.
In the olden days, this would break the ability to ‘jump to source' — something that is crucial to me being able to move throughout my code with ease and speed. WebStorm is clever and will resolve these hops (it will ‘know' that I don't want to jump into the index.js file, I want to jump all the way to the Link.js file), but if your text editor isn't so clever, this might leave you with a lot of index.js files open, or jumping to source might not work at all.
So before subscribing to an approach, try it out and see if it's going to be a hindrance to the way you work.
.js vs .jsx extensions
Until recently I'd always used .jsx extensions for any file that contained JSX, and used .js for anything that was vanilla JavaScript. This gave a clear distinction when opening/viewing files and as a bonus, you'll get proper JSX syntax highlighting in GitHub.
However Facebook suggests not using the .jsx extension, so I've recently been using just .js and I'm glad I didn't waste too much time weighing the pros and cons because it makes zero difference to me.
I recommend flipping a coin to decide.
Index files for utils
As a result of writing this article, and really thinking about what matters to me, I have actually made a change to one small aspect of my personal preference for app structure.
I used to create an index.js file for my utils, like so:
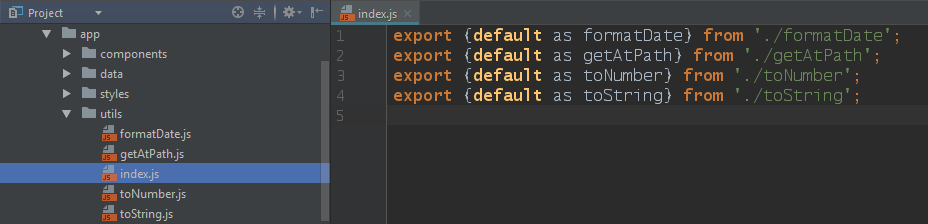
So that I could import multiple utilities in one go like this:
So neat!
Whenever I added a new util (0.8 times per week) I would simply add the util file and a new entry in the index file. Whenever I saw a PR that added a util and forgot to add it to index.js I would remind the developer to add that in. I would also occasionally discover utilities that weren't in index.js, so would have to add them myself. Such an elegant solution.
For some reason it took until September 2017 for me to realise that this only added complexity. And that actually ditching the index.js and doing this was better:
It's fewer lines, one less file, and one less thing to explain to new developers.
But those long import paths burn my eyes, so let's take a look at a couple of solutions. There are two of them, as is often the case with couples.
Solution one is to use Webpack's alias resolving to refer to my utils directory without a relative path. Here I've mapped Utils to src/app/utils; the result is pretty, and aligns nicely with the way I import other utilities.
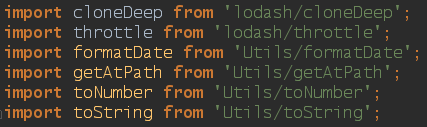 Capital ‘U' by convention to differentiate it from npm packages
Capital ‘U' by convention to differentiate it from npm packages
In the olden days this would confuse some text editors because they wouldn't know what or where Utils/formatDate was. My IDE is clever and reads my Webpack config (it actually runs webpack under the hood), and makes the connection to the correct file (so I can jump to source, get autocomplete, etc).
(The theme continues: the tools we use and the way we use them should most definitely be taken into account when thinking about how to structure our apps.)
So… it's a beautiful, neat, solution. But what's behind the scenes?
This is a nice solution but it has two negative impacts.
- It adds complexity. We now have more moving parts to achieve the exact same outcome.
- It reduces clarity. Someone unfamiliar with your Webpack config can't look at an import statement and know what it's referring to.
The second solution is to convince myself that I don't care about the dots and leave them as they are.
To convince myself, I thought about how often I type out an import path, and as it turns out it's exactly as often as I make coffee. Then I thought about how really, it's not so hard to type eight dots and five slashes, compared to the time it takes to put the little coffee pod in the machine, measure out a teaspoon of sugar into a cup, milk the cow just a little bit (shout out to Daisy) and press the picture of a cup.
The trade-offs between these two options are representative of many different decisions (in life, and in programming), so this feels like a good time to debut my clarity/obscurity-simplicity/complexity matrix.
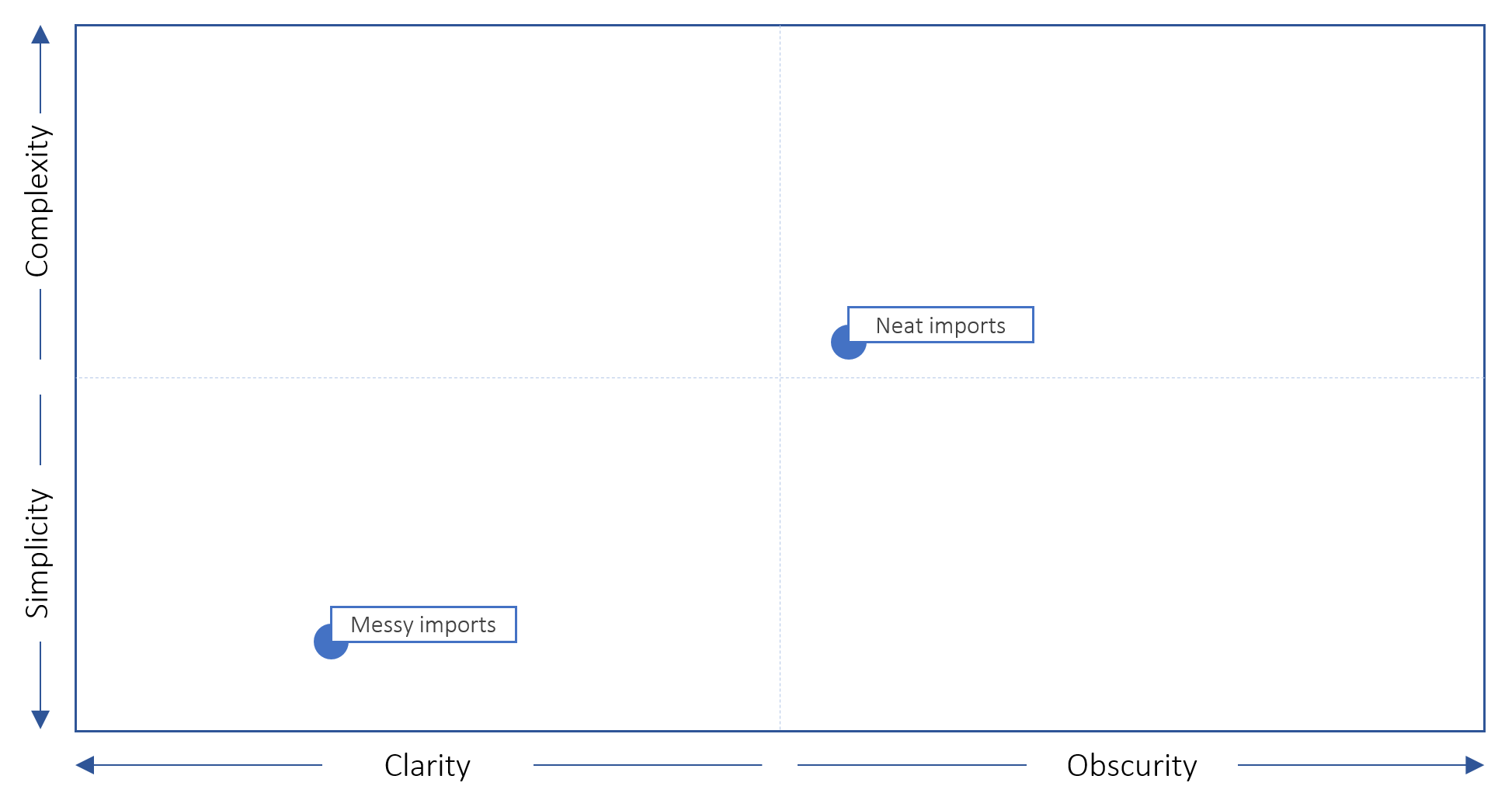 ClObSiCo for short
ClObSiCo for short
For me, the decision between these two is a close call. In the end though, I will favour clarity and simplicity wherever possible, so even though having ../../../../ in an import statement is an eyesore, it is the clear and simple winner.
Index files for components
It's not my cup of tea, but another thing you might like to do in the battle against the import dots is to create a library for your components.
Maybe this gets your motor running:
You already know how to do this in your Webpack config:
Then in your components directory add an index.js file with a row for each component like so:

Boom.
n exports per file
Having one export per file — where the thing being exported and the filename are the same — works a lot of the time and I think is a good general rule for components and utility functions.
But I don't think this works for constants. I also like to start with a single file for all action creators, until it becomes a burden. Same for reducers. In my experience it doesn't make much difference whether you have eight, 10-line reducers in a single file or eight different files.
If you think it has a significant impact on how quickly you can locate a particular piece of code, then do what works for you. Heck, maybe Redux ducks make your boat float. Sure, whatever.
What works for the team
Now seems like a good time to explain the title of this post. If you're working on a project that is just you, then you might be able to find a React structure that is 100% correct, for you. In fact I think it's well worth aiming for this.
But the more people there are on a team, the less likely it is that you'll find something ‘optimal', and the more likely other factors will come into play.
The big one is compromise. Be aware of distinction bias. You can probably tell from the above that for some items I would be happy to go another way if a team member expressed a strong preference. If someone really wanted to use .jsx extensions or have a Utils alias, I'd be cool with that because although it's not my preference, it won't reduce my ability to work quickly. But if someone really really wanted every damn file to be named index.js then it'd be on like Donkey Kong.
Another consideration: if you have, say, 30 developers on a team and you're starting a new project, you might want to structure it as closely to previous projects as possible, no use reinventing the wheel. Or maybe you'll want to learn from past mistakes and have a different structure, fix that badly-invented wheel.
Another little thing: as your team gets bigger, git conflicts will become a bigger part of your day, and erring on the side of smaller files will be a benefit.
If you have a mixture of skill levels on the team, that should encourage you to favour simplicity and clarity. On the flip side, if you have a team of seasoned front end engineers (mmm, seasoned), then go nuts and make it as complex as you like. As long as everyone is on the same wavelength, it doesn't matter how weird it looks from the outside.
Summary
I have a confession to make. I always struggle with summaries. It's like, I just wrote you a whole blog post, what more do you want from me!
So it's not a summary, but I think the most interesting aspect of all the different approaches to application structure is the way people deal with disagreements. There's a whole class of internet comments that can be summarised as “I disagree and that makes me ANGRY”. Which is a pity, because when two reasonable people disagree, there's very often something interesting going on, just waiting to be discovered.
And since I'm already doing a terrible job of wrapping this up, how about a movie recommendation? If you liked District 9, and haven't watched Chappie yet, then watching Chappie is something you should immediately go and do.
Thanks for reading. Bye!