
Cách Javascript hoạt động P14: Parsing, Abstract Syntax Tree & mẹo giảm tối đa thời gian parse
Chào các bạn đến với bài thứ 14 trong series đục khoét và khám phá Javascript cũng như các thành phần của nó. Trong quá trình xác định và tìm hiểu các thành phần cốt lõi, tác giả cũng chia sẻ một số nguyên tắc mà họ đang dùng để xây dựng SessionStack, một ứng dụng Javascript hướng đến sự mạnh mẽ, hiệu năng cao và ổn định.
Khái quát
Chúng ta đều biết rằng những thứ lộn xộn có thể hợp thành 1 thứ lớn hơn gọi là Javascript. Một đoạn code không chỉ có thể di chuyển qua mạng mà nó còn phải được parse, biên dịch sang bytecode và cuối cùng thực thi. Trong các bài trước, chúng ta đã thảo luận về những thứ chẳng hạn như JS engine, runtime, callstack cũng như engine V8 được dùng chủ yếu trong Chrome và NodeJS. Tất cả đều đóng vai trò quan trọng trong toàn bộ quá trình thực thi của Javascript. Chủ đề mà chúng ta sẽ tìm hiểu hôm nay cũng không kém quan trọng: chúng ta sẽ nghiên cứu xem làm thế nào mà đa số các engine JS parse văn bản thành một thứ gì đó có nghĩa đối với máy móc, những gì xảy ra sau đó và làm thế nào để web developer như chúng ta có thể tận dụng những kiến thức đó làm điểm mạnh.
Ngôn ngữ lập trình hoạt động như thế nào?
Cùng lùi lại 1 chút và xem xem ngôn ngữ lập trình hoạt động thế nào. Không cần biết là bạn đang xài ngôn ngữ gì, bạn sẽ luôn cần một phần mềm có thể đọc mã nguồn và khiến cho máy tính thực hiện một điều gì đó. Phần mềm này có thể là trình thông dịch hoặc trình biên dịch.
Không cần biết bạn đang xài ngôn ngữ thông dịch (Javascript, Python, Ruby) hay ngôn ngữ biên dịch (C#, Java, Rust), luôn luôn có 1 điểm chung giữa chúng: parse đoạn mã nguồn từ văn bản gốc thành một cấu trúc dữ liệu được gọi là Abstract Syntax Tree (AST).
Các AST không chỉ thể hiện mã nguồn dưới dạng cấu trúc mà chúng còn đóng vai trò quan trọng trong phân tích ngữ nghĩa, chính là nơi mà trình biên dịch xác nhận tính đúng đắn và cách sử dụng phù hợp của chương trình cũng như các phần tử của ngôn ngữ. Về sau, các AST được dùng để sinh ra bytecode hoặc mã máy.
Các ứng dụng AST
AST không chỉ được dùng trong trình thông dịch và trình biên dịch ngôn ngữ, chúng còn có nhiều ứng dụng trong thế giới máy tính. Một trong số đó là dùng chúng là phân tích code tĩnh. Các nhà phân tích tĩnh không thực thi code, họ cần hiểu cấu trúc của code. Ví dụ: bạn muốn triển khai một công cụ tìm sự giống nhau giữa các kiến trúc code để từ đó bạn có thể refactor nhằm giảm sự trùng lặp. Bạn có thể làm việc này bằng cách so sánh string bình thường nhưng cách triển khai thì khá cơ bản và giới hạn.
Một cách tự nhiên, nếu bạn có hứng thú triển khai một công cụ thì bạn không cần phải viết riêng cho nó 1 cái parser. Có rất nhiều triển khai mã nguồn mở có sẵn có khả năng tương thích toàn diện với thông số kỹ thuật của Ecmascript. Ví dụ: Esprima và Acorn. Cũng có rất nhiều công cụ có thể giúp ta với sản phẩm nhận được từ parser, hay còn gọi là AST. Các AST cũng được dùng nhiều trong phần triển khai của các code transpiler. Ví dụ: bạn cần triển khai một bộ transpiler để chuyển code Python thành Javascript. Ý tưởng cơ bản là ta cần một Python transpiler để sinh ra cây AST - thứ mà ta cần để có thể sinh ra code Javascript sau này.
Bạn có thể tự hỏi, làm sao như vậy được? Điểm mấu chốt là các AST chỉ là một điểm khác biệt về cách thể hiện một vài ngôn ngữ. Trước khi parse, nó thể hiện dưới dạng văn bản đi kèm theo một số quy luật nhất định để hình thành nên 1 ngôn ngữ. Sau khi parse, nó thể hiện dưới dạng một kiến trúc dạng cây chứa chính xác cùng 1 thông tin với văn bản đầu vào. Vì thế, bạn có thể luôn luôn có thể làm ngược lại và go back về dạng biểu diễn văn bản.
Javascript parsing
Giờ thì cùng tìm hiểu cây AST được xây dựng như thế nào. Đầu tiên ta có một hàm Javascript đơn giản như sau:
1 | function foo(x) { |
Parser sẽ sản sinh ra cây AST như sau:
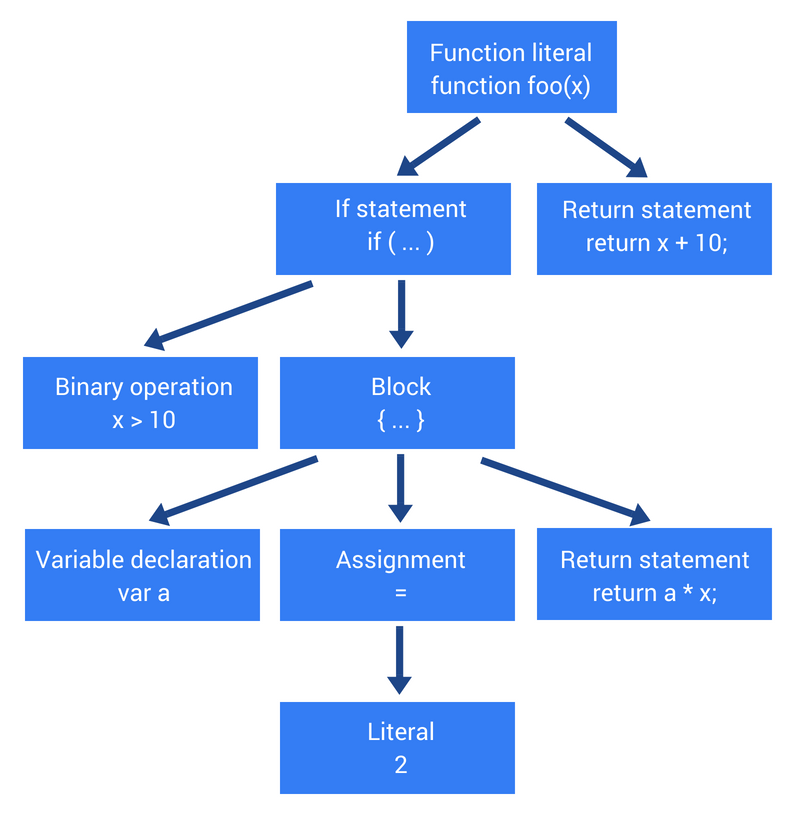
Lưu ý rằng vì mục đích dễ nhìn và đẹp thì hình trên chỉ là phiên bản tối giản của sản phẩm thực sự từ parser. Cây AST thật sẽ phức tạp hơn rất nhiều. Tuy nhiên, mục đích của chúng ta là có được ý tưởng cơ bản về việc mã nguồn sẽ biến thành cái gì trước khi nó được thực thi. Nếu bạn muốn xem cây AST thứ thiệt trông như thế nào thì bạn có thể vào đây. Đó là 1 công cụ online, bạn chỉ cần nhập code Javascript vào và nó sẽ sinh ra cây AST cho đoạn code đó.
Bạn sẽ tự hỏi tại sao chúng ta cần biết về cách hoạt động của Javascript parser. Sau tất cả thì nó thuộc về trách nhiệm của trình duyệt. Và về mặt nào đó thì đúng là như thế. Tuy nhiên, bạn có thể xem hình bên dưới, đó là đồ thị biểu diễn tổng thời gian phân phối cho từng bước trong quá trình thực thi code Javascript. Hãy nhìn kỹ hơn và thử xem có thấy được gì thú vị không.
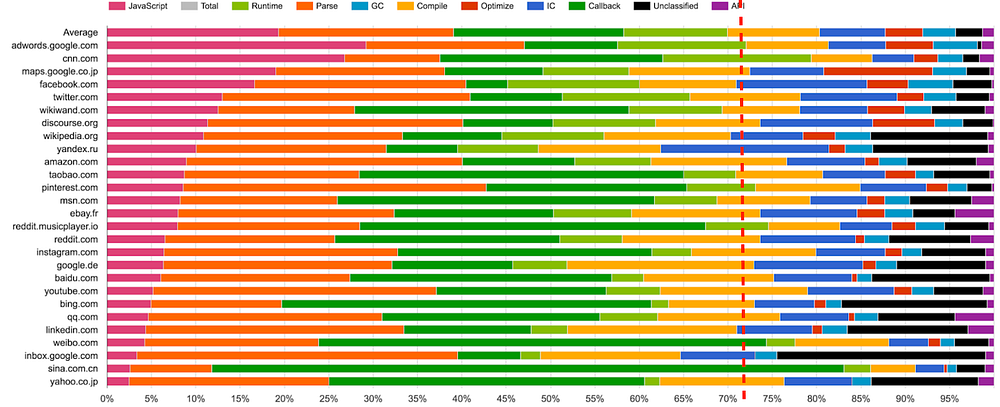
Bạn có thấy được không? Nhìn kỹ xem. Trung bình thì trình duyệt chiếm khoảng 15-20% tổng thời gian thực thi để parse Javascript. Những con số này không phải là bịa đặt. Chúng là số liệu thống kê từ những ứng dụng và website có thật đang bằng cách này hay cách khác sử dụng Javascript. Giờ thì 15% có vẻ như không nhiều lắm, nhưng tin tôi đi, nó có giá trị đấy. Một app SPA tiêu chuẩn sẽ load khoảng 0.4MB code Javascript và trình duyệt tiêu tốn xấp xỉ 370ms để parse nó.
Thêm một lần nữa, bạn sẽ nói rằng nó chẳng đáng bao nhiêu thời gian cả. Và rõ ràng con số đó quá nhỏ. Tuy nhiên nhớ kỹ rằng đây chỉ là thời gian cần để parse code Javascript thành cây AST. Chưa bao gồm thời gian thực thi chính nó hay bất kỳ tiến trình nào diễn ra trong khi load trang (ví dụ như CSS & HTML rendering). Và tất cả thông số này mới chỉ thể hiện cho desktop. Khi chúng ta đi sâu hơn trên mobile, mọi thứ sẽ trở nên phức tạp hơn nhiều. Thời gian dành cho việc parse trên mobile thường có thể nhiều hơn 2-5 lần so với trên desktop.
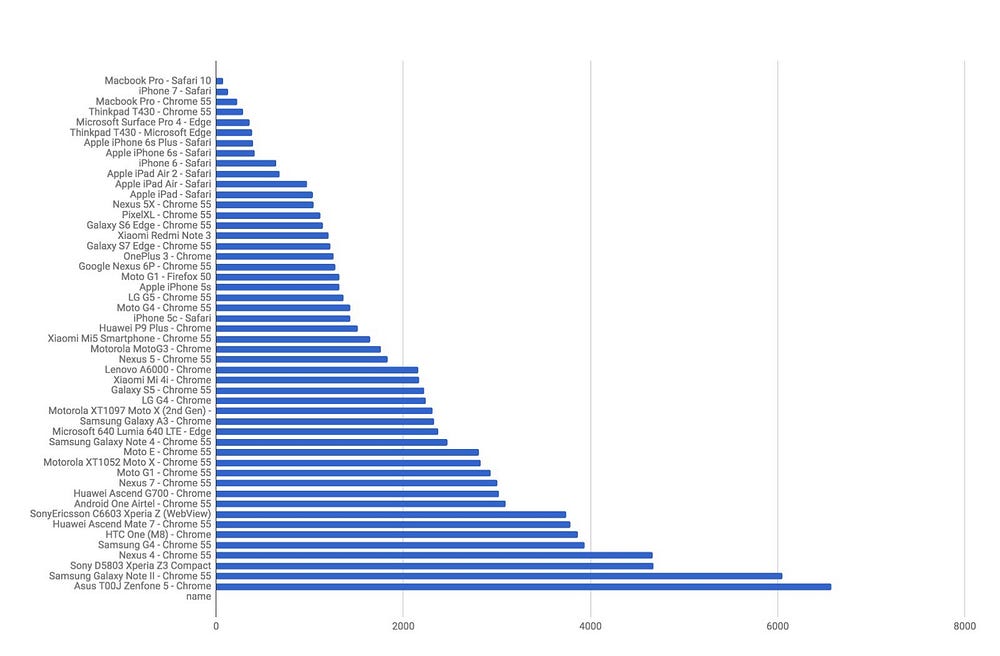
Đồ thị trên thể hiện thời gian parse của 1 gói code Javascript 1MB trên rất nhiều thiết bị mobile & desktop thuộc nhiều phân khúc khác nhau.
Gì nữa nào? Web app đang càng trở nên phức tạp theo từng phút cũng như càng có nhiều business logic phải xử lý ở phía client để có thể mang lại trải nghiệm giống hệt như native app. Bạn có thể dễ dàng hiểu được những điều đó ảnh hưởng như thế nào đến website/wepapp của bạn. Tất cả những gì bạn cần là mở dev tool của trình duyệt lên và để nó đo đạc lượng thời gian dành cho parsing, biên dịch và mọi thứ diễn ra trên trình duyệt cho tới khi trang web được load hoàn toàn.
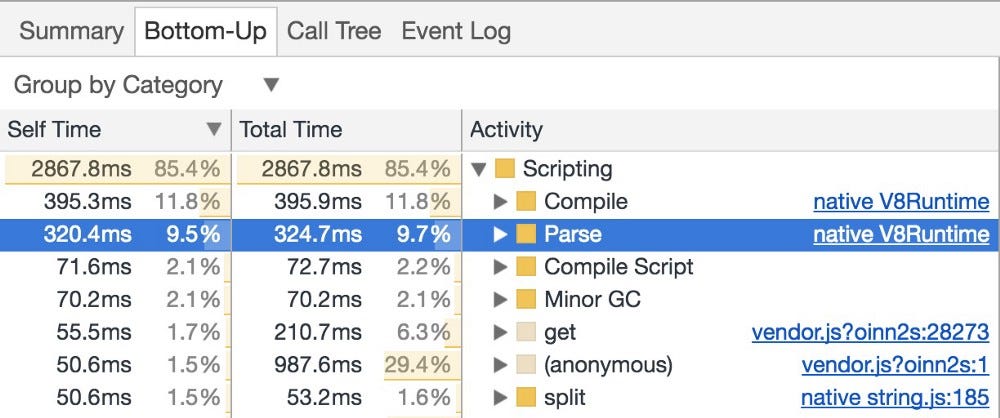
Thật không may, không có dev tool nào cho các trình duyệt mobile. Nhưng đừng lo lắng, điều này không có nghĩa rằng bạn không thể làm gì được. Đây là lý do những công cụ như DeviceTiming tồn tại. Nó có thể giúp bạn đo đạc thời gian parse và thực thi cho các đoạn code trong một môi trường kiểm soát. Nó hoạt động bằng cách gói gọn code local với đoạn code đo lường, vì thế nên mỗi lần trang web của bạn được truy cập từ các thiết bị khác nhau, bạn có thể đo đạc thời gian parse và thực thi.
Điều tốt là engine Javascript đã làm rất nhiều thứ nhằm tránh cách công việc thừa thãi và tối hưu hóa nhiều hơn. Dưới đây là 1 vài thứ mà các engine của những trình duyệt lớn đã làm.
Ví dụ với V8, nó thực hiện script streaming & code caching. Script streaming nghĩa là các đoạn code bất đồng bộ & bị trì hoãn sẽ được parse trong 1 tiến trình riêng ngay khi quá trình download bắt đầu. Nó giúp cho quá trình parsing gần như hoàn thành ngay lập tức sau khi đoạn code (script) được tải xong. Kết quả là các trang sẽ load nhanh hơn khoảng 10%.
Code Javascript thường được biên dịch thành bytecode mỗi khi có một lượt truy cập trang. Tuy nhiên, cục bytecode này lại bị bỏ đi khi người dùng truy cập đến trang khác. Điều này xảy ra vì code được biên dịch phụ thuộc rất nhiều vào trạng thái và ngữ cảnh của máy tại thời điểm biên dịch. Đây là lý do Chrome 42 giới thiệu bytecode caching (bộ đệm bytecode). Đây là một kỹ thuật lưu trữ code đã biên dịch ở local để khi user quay trở lại trang cũ trước đó thì tất cả mọi hoạt động như download, parse, biên dịch… có thể bỏ qua. Nó cho phép Chrome tiết kiệm 40% thời gian parse & thực thi. Thêm nữa, kết quả nó tiết kiệm pin nhiều hơn nếu chạy trên các thiết bị mobile.
Trong Opera, engine Carakan có thể dùng lại kết quả biên dịch từ chương trình khác vừa mới được biên dịch gần đây. Không có các yêu cầu cụ thể nào về việc code phải đến từ cùng 1 trang hay domain. Kỹ thuật caching này thực sự rất hữu ích và có thể hoàn toàn bỏ qua bước biên dịch. Nó phụ thuộc vào hành vi tiêu chuẩn của user và ngữ cảnh lươt web: mỗi khi user thực hiện cùng chuỗi hành trình với một user khách trên app/website thì cùng 1 đoạn code Javascript sẽ được tải. Tuy nhiên, Opera đã sớm thay thế Carakan bằng Google V8.
Bộ engine SpiderMonkey của Firefox không lưu cache bất kỳ thứ gì. Nó đại khái là chuyển qua dùng một thao tác giám sát để đếm xem 1 đoạn code Javascript được thực thi bao nhiêu lần. Dựa trên số đếm này nó xác định phần nào của code đang hot và cần được tối ưu hóa.
Rõ ràng có một số người lựa chọn không làm gì cả. Maciej Stachowiak, lead developer của Safari, chỉ định rằng Safari không thực hiện bất kỳ hoạt động cache nào cho bytecode đã biên dịch. Có vẻ như họ đã có cân nhắc về việc này nhưng không triển khai nó bởi vì nó chỉ nhỏ hơn 2% tổng thời gian thực thi.
Những hoạt động tối ưu hóa không trực tiếp ảnh hưởng đến chuyện parsing của code Javascript nhưng chúng chắc chắn đang làm tốt nhất có thể để bỏ qua nó một cách hoàn toàn. Còn cách tối ưu hóa nào tốt hơn là tối ưu hóa hoàn toàn?
Có nhiều thứ chúng ta có thể làm để cải thiện thời gian load app ban đầu. Ta có thể làm tối giản lượng code Javascript đang sử dụng: ít code, ít parse, ít thực hi. Để làm được điều này, ta cần đưa ra vừa đúng lượng code cần thiết cho một tính năng cụ thể thay vì load 1 cục thiệt to lớn và dùng nó vào mọi thứ. Ví dụ, pattern PRPL có thuyết giảng về mô hình chuyển giao code như vậy. Nói cách khác, ta có thể kiểm tra các dependency và xem nếu như có gì đó thừa thãi không cần thiết làm chậm code của chúng ta. Về phần này thì hi vọng là sẽ có 1 topic riêng để nói về nó.
Mục đích của bài viết này là để thảo luận chúng ta - những web developer - có thể làm được gì để giúp cho Javascript parser có thể chạy nhanh hơn. Và chính là đây, các Javascript parser hiện đại sử dụng các phỏng đoán để xác định nếu một đoạn code cụ thể nào đó chuẩn bị được thực thi ngay hoặc quá trình thực thi sẽ bị tạm ngưng và dời lại trong một thời điểm khác.
Dựa trên các phỏng đoán, parser sẽ làm hoặc là eager parsing (parse nhanh) hoặc là lazy parsing (parse từ từ). Eager parsing chạy xuyên suốt các hàm nào cần được biên dịch tức thời. Nó thực hiện 3 việc chính: xây dựng cây AST, xây dựng hệ thống cấp bậc (hierarchy) cho scope và tìm tất cả các lỗi cú pháp.
Lazy parsing thì ngược lại, nó chỉ được dùng cho các hàm chưa cần được biên dịch. Nó không xây dựng cây AST và cũng không tìm lỗi cú pháp. Nó chỉ xây dựng hệ thống cấp bậc cho scope và tiết kiệm được một nửa thời gian so với eager.
Rõ ràng đây không phải là ý tưởng mới. Kể cả trình duyệt như IE9 cũng hỗ trợ tối ưu hóa mặc dù nó chạy hơi thô sơ nếu như so với cách mà parser ngày nay hoạt động.
Giờ thì cùng xem một ví dụ về cách nó hoạt động. Giả sử ta có đoạn code sau:
1 | function foo() { |
Giống như ví dụ trước, code được đưa vào parser để phân tích cú pháp và trả ra cây AST. Vậy thì đây là những gì thực hiện theo từng dòng:
Định nghĩa hàm bar nhận 1 biến x và nó có 1 câu lệnh return trả về kết quả của phép tính cộng giữa x và 10.
Định nghĩa hàm baz nhận 2 biến (x và y). Nó có 1 câu lệnh return. Hàm này trả về kết quả của phép tính cộng giữa x và y.
Gọi hàm baz với 2 đối số là 100 và 200.
Tạo ra 1 lời gọi hàm đến console.log với giá trị là kết quả của lời gọi hàm trước đó.
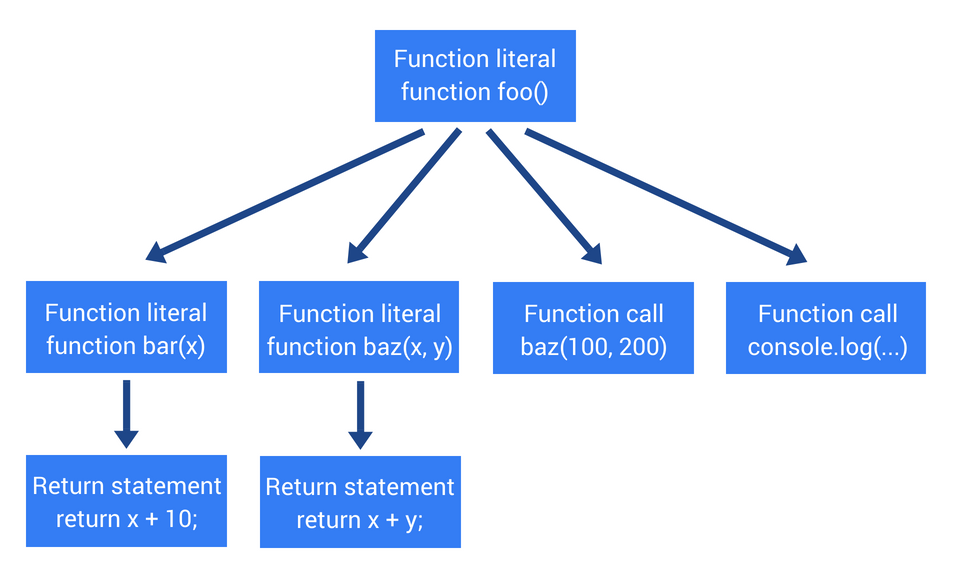
Điều gì vừa xảy ra vậy? Parser thấy có một định nghĩa hàm foo, định nghĩa bar và 1 hàm baz, một lời gọi đến hàm baz, một lời gọi đến hàm console.log. Chờ đã… có một số thứ parser đã làm hoàn toàn không liên quan. Đó là việc parse hàm bar. Tại sao lại không liên quan? Bởi vì hàm bar chưa bao giờ được gọi (ít nhất là cho tới thời điểm này). Đây chỉ là một ví dụ đơn giản và có vẻ như không bình thường nhưng nó xuất hiện trên rất nhiều app thực, có rất nhiều hàm được định nghĩa nhưng không bao giờ dùng đến.
Thay vì parse hàm bar, chúng ta có thể đánh dấu nó đã được khai báo nhưng không chỉ ra cụ thể nó làm gì. Parsing sẽ diễn ra khi cần thiết ngay trước khi hàm được thực thi. Và dĩ nhiên là lazy parsing cũng vẫn cần thiết để tìm toàn bộ body của hàm và tạo một khai báo cho hàm đó. Nó không cần cây cú pháp bởi vì nó vẫn chưa được xử lý. Thêm nữa, bộ nhớ heap vẫn chưa được cấp phát (phần này cũng chiếm 1 lượng tương đối trong tài nguyên hệ thống). Nói ngắn gọn thì bỏ qua một số bước trên sẽ cải thiện đáng kể hiệu năng.
Vậy nên nhìn lại ví dụ trên, ta có cây AST mới sẽ như thế này:
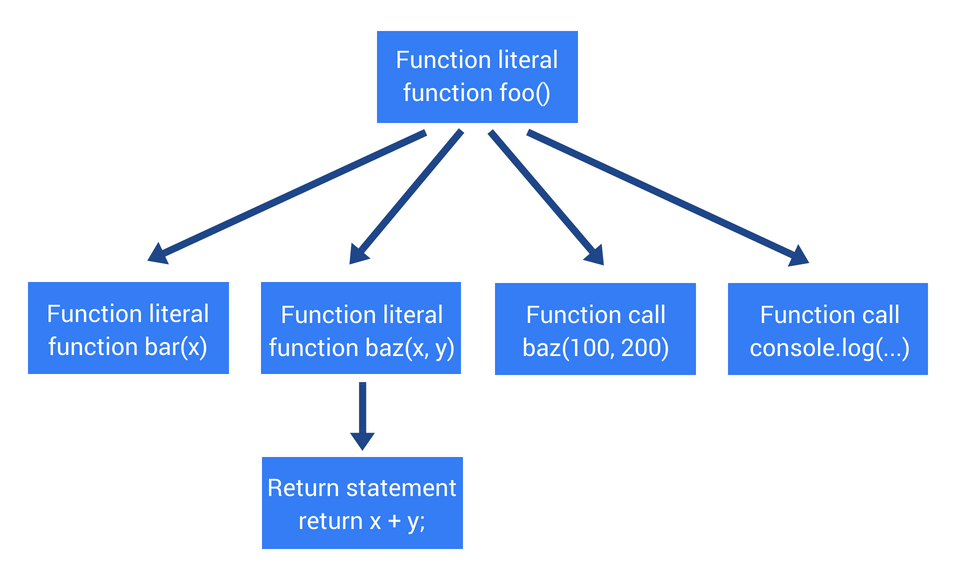
Lưu ý rằng hàm bar được khai báo và chấp nhận, nhưng chỉ có thế thôi. Chúng ta không làm gì với body của hàm. Trong trường hợp này, body của hàm chỉ có 1 câu lệnh return. Tuy nhiên, trong hầu hết các ứng dụng thực tế, nó có thể lớn hơn rất nhiều, bao gồm nhiều câu lệnh return, điền kiện, vòng lặp, định nghĩa các biến và kể cả các khai báo hàm lồng nhau. Tất cả những thứ này sẽ gây tốn thời gian cũng như tài nguyên hệ thống bởi vì hàm không bao giờ được gọi.
Đây là một ý tưởng cực kỳ đơn giản nhưng trong thực tế công việc thì việc triển khai nó lại không đơn giản. Dưới đây là một ví dụ mà chắc chắn không phải là trường hợp duy nhất. Toàn bộ phương thức sử dụng các hàm, vòng lặp, điều kiện, object, vân vân. Cơ bản là toàn bộ code cần được parse.
Ví dụ một mô hình phổ biến để triển khai Javascript module:
1 | var myModule = (function() { |
Mô hình này dễ dàng nhận ra bởi các Javascript parser hiện đại và là một dấu hiệu cho thấy code bên trong có thể dùng eager parsing.
Vậy tại sao parser không mặc định lazy parsing? Nếu có gì đó được parse lazy thì nó phải được thực thi ngay lập tức và điều này thực sự gây ra sự chậm chạp. Một lazy parse được thực hiện và ngay sau đó là eager parse. Kết quả là tốc độ chậm hơn 50% khi so sánh với chỉ dùng 1 eager parse.
Đến lúc này ta đã có kiến thức cơ bản về phía hậu trường, giờ thì thử xem chúng ta có giúp gì cho parser được không. Ta có thể viết code theo cách mà các hàm có thể được parse tại thời điểm phù hợp. Có một pattern được xài chung giữa các parser: đóng gói hàm bên trong dấu ngoặc (). Đây luôn là một dấu hiệu tích cực cho parser hiểu rằng hàm sẽ được thực thi ngay lập tức. Nếu parser bắt gặp một dấu mở ngoặc ( và ngay liền sau đó là một định nghĩa hàm, nó sẽ parse eager hàm đó. Chúng ta có thể giúp parser bằng cách khai báo hàm một cách tường minh như vậy hàm sẽ được thực thi ngay lập tức.
Giả sử ta có hàm Javascript như sau:
1 | function foo(x) { |
Bởi vì không có dấu hiệu rõ ràng rằng hàm sẽ được thực thi ngay lập tức nên trình duyệt sẽ thực hiện lazy parse. Tuy nhiên, chúng ta biết rằng như vậy là không đúng nên ta có thể làm 2 việc.
Đầu tiên, ta lưu hàm vào trong 1 biến:
1 | var foo = function foo(x) { |
Lưu ý rằng ta vẫn giữ lại tên hàm foo giữa từ khóa function và dấu mở ngoặc (. Điều này tuy không cần thiết nhưng bạn bên làm vì trong trường hợp xử lý biệt lệ, stacktrace sẽ hiện ra tên cụ thể của hàm thay vì một chữ
Parser vẫn thực hiện lazy parse. Ta có thể ngăn chặn điều này bằng cách thêm một chi tiết nhỏ: gói hàm đó lại trong dấu ngoặc.
1 | var foo = (function foo(x) { |
Tại thời điểm này, khi parser thấy dấu mở ngoặc ( ngay trước từ khóa function nó sẽ ngay lập tức thực hiện eager parsing.
Sẽ hơi khó để quản lý bởi vì chúng ta sẽ cần phải biết trong trường hợp nào thì parser chọn parse lazy hay eager. Thêm nữa ta cần phải suy nghĩ và tìm hiểu một hàm cụ thể nào đó có được gọi ngay lập tức hay không. Chúng ta chắc chắn không muốn làm vậy. Ít nhất thì nó sẽ làm cho code khó đọc & khó hiểu hơn. Công cụ như Optimize.js có thể giúp ta rất nhiều. Mục đích duy nhất của nó là tối ưu hóa thời gian loaing ban đầu của code Javascript. Chúng thực hiện phân tích code tĩnh và chỉnh sửa lại để đóng gói những hàm nào cần được thực thi bên trong dấu ngoặc (), trình duyệt sẽ có thể parse eager và chuẩn bị chúng sẵn sàng để thực thi.
Chúng ta có thể tiếp tục code bình thường và có đc đoạn code sau:
1 | (function() { |
Mọi thứ có vẻ tốt, hoạt động đúng như mong đợi và nhanh nữa. Bởi vì có dấu mở ngoặc ( trước khi khai báo hàm. Rất tuyệt. Dĩ nhiên rồi, trước khi đưa lên production ta cần minify để tiết kiệm dung lượng. Đoạn code sau là sản phẩm cuối cùng:
1 | !function(){console.log('Hello, World!')}(); |
Một lần nữa, chúng có vẻ tốt phải không? Code hoạt động y như cũ. Nhưng có gì đó thiếu thiếu. Trình minify đã gỡ dấu ngoặc đóng gói bên ngoài hàm và thay vào đó thêm 1 dấu chấm than ! ngay trước hàm. Điều này nghĩa là parser sẽ bỏ qua nó và thực hiện lazy parse. Trên hết thì để có thể thực thi hàm nó sẽ thực hiện eager parse ngay sau khi lazy parse. Vậy thì lại làm code chạy chậm hơn. May mắn thay, chúng ta có những công cụ như Optimize.js giúp ta trong những trường hợp này. Truyền đoạn code đã minify vào Optimize.js và đây là kết quả đầu ra:
1 | !(function(){console.log('Hello, World!')})(); |
Giờ thì ta đã có thành phẩm tốt nhất: code được minify và parser dễ dàng xác định được những hàm nào cần parse eager hàm nào cần parse lazy.
Biên dịch trước (Pre-compilation)
Vậy tại sao ta không thực hiện toàn bộ các bước này ở phía server. Dĩ nhiên thì sẽ tốt hơn nếu chúng ta thực hiện 1 lần rồi triển khai kết quả cho tất cả client, thay vì bắt mỗi client phải thực hiện nó mỗi lần chạy. Thật ra thì có những thảo luận về việc engine nên cung cấp một cách để thực thi những đoạn code đã được biên dịch trước để đỡ tốn thời gian cho trình duyệt.
Về bản chất thì ý tưởng chính là có một công cụ ở phía server có thể sinh ra bytecode rồi truyền trực tiếp về phía client và thực thi. Nếu thực sự được như vậy thì thời gian khởi động app phía client sẽ được cải thiện đáng kể. Nghe rất hấp dẫn, nhưng mọi việc không đơn giản như vậy.
Điều này có thể gây ra hiệu ứng ngược lại, hiệu ứng lớn là đằng khác, vì hầu hết code có thể sẽ cần phải được ký & xử lý vì những lý do bảo mật. Đội ngũ V8 đang làm việc nội bộ với nhau để tránh re-parsing để quá trình biên dịch trước sẽ có lợi ích như thế.
Một vài mẹo vặt bạn có thể thực hiện để app chạy nhanh hơn
- Kiểm tra các dependency. Loại bỏ những thứ không cần thiết.
- Chia nhỏ code thành nhiều phần nhỏ hơn thay vì load nguyên 1 cục bự.
- Trì hoãn quá trình load Javascript nếu có thể. Bạn chỉ cần load phần code nào cần thiết dựa trên route hiện tại mà thôi.
- Dùng dev tool & DeviceTiming để tìm hiểu phần nào đang bị thắt cổ chai.
- Dùng công cụ như Optimize.js để giúp parser quyết định khi nào nên parse eager & lazy.
SessionStack là công cụ hỗ trợ tái tạo lại mọi thứ xảy ra đối với người dùng cuối tại thời điểm họ gặp phải vấn đề khi đang tương tác với webapp. Công cụ này không dựng lại phiên làm việc đó thành 1 video thật mà chỉ giả lập tất cả các sự kiện trong một môi trường sandbox trên trình duyệt. Điều này có ý nghĩa nhất định, ví dụ trong trường hợp codebase của page hiện tại lớn và phức tạp.
Những kỹ thuật trên là những thứ mà team tác giả gần đây kết hợp trong quá trình phát triển SessionStack. Những tối ưu hóa đó cho phép họ load SessionStack nhanh hơn. SessionStack chạy càng nhanh nó càng có thể giải phóng tài nguyên của trình duyệt nhanh hơn và mang lại trải nghiệm một cách liên tục & tự nhiên cho người dùng khi họ load & xem lại các session làm việc.
Source: https://blog.sessionstack.com/how-javascript-works-parsing-abstract-syntax-trees-asts-5-tips-on-how-to-minimize-parse-time-abfcf7e8a0c8